UPDATE 语句执行流程解析
本文将会详细介绍 MiniOB 中 UPDATE 语句的执行流程,接下来将以 update t1 set c1 =1 为例进行讲解。
create table t1 (c1 int);
insert into t1 values(2);
update t1 set c1 = 1;
一. SQL 语句执行流程
在 SELECT 语句执行流程解析中我们已经介绍了 MiniOB 中一条 SQL 语句的执行流程,接下来我们将从 update 语句的词法语法解析开始讲起。
二. 词法语法解析阶段阶段
函数:parse_stage_.handle_request()
词法分析与语法分析是编译原理中的相关知识,在 MiniOB 中,词法文件是 lex_sql.l,语法文件是 yacc_sql.y,同学们可以先学习一下官方的文档 SQL Parser - MiniOB
- 在词法分析阶段,会将输入的 sql 语句分解为一个个 token,传递给语法分析器;如下图,flex 会将
UPDATE字符串(忽略大小写)识别为 tokenUPDATE传递给 yacc/bison 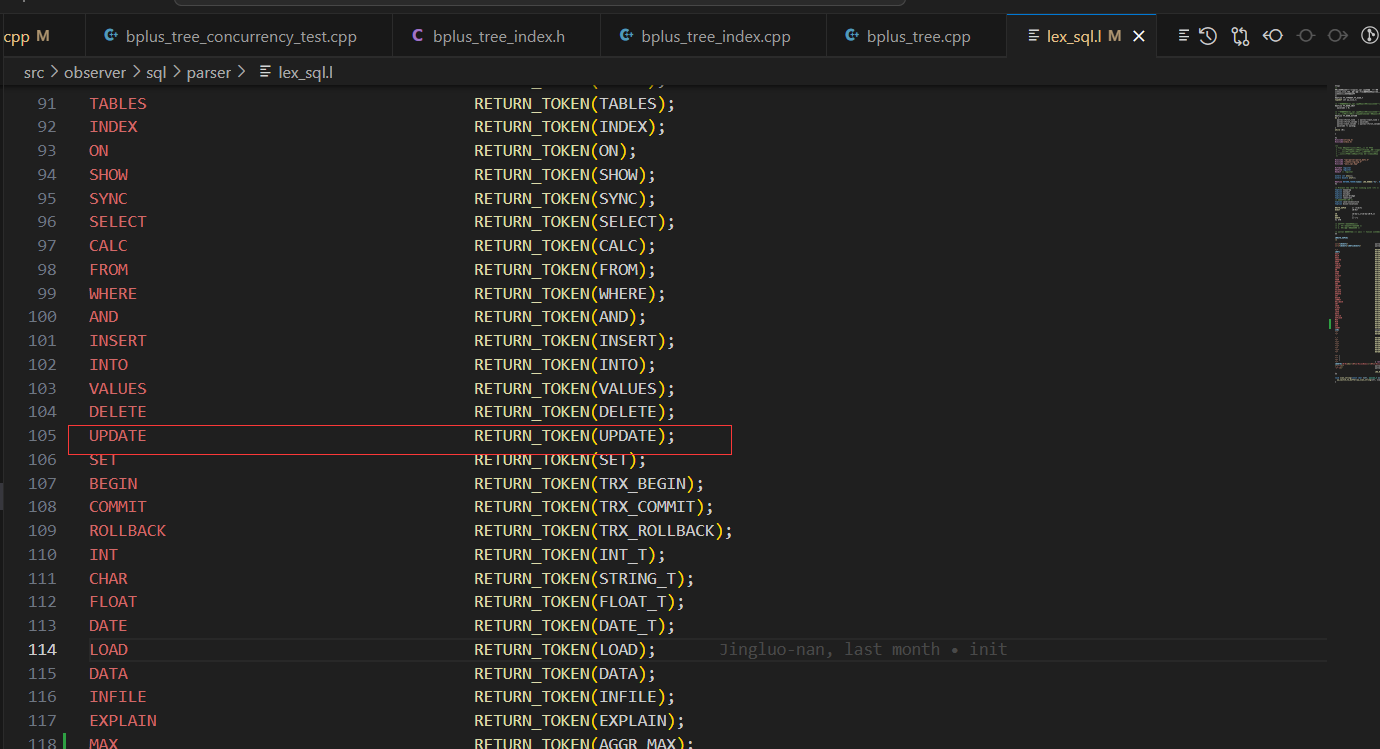
-
在语法分析阶段,会根据语法文件,对词法分析生成的 token 进行归约,生成相应的 SqlNode
针对
update t1 set c1 =1这条 sql,对应的是如下的语法规则(文件 yacc_sql.y 中):update_stmt: /* update 语句的语法解析树*/ UPDATE ID SET ID EQ value where { $$ = new ParsedSqlNode(SCF_UPDATE); $$->update.relation_name = $2; $$->update.attribute_name = $4; $$->update.value = *$6; if ($7 != nullptr) { $$->update.conditions.swap(*$7); delete $7; } free($2); free($4); } ;
对于 update t1 set c1 =1 这条sql,以上语法规则中:
UPDATE对应于updateID对应于t1SET对应于setID对应于c1EQ对应于=value对应于1
经过词法、语法解析后, update 内容会存储到一个 UpdateSqlNode 对象中
我们来看一下这个结构体的成员变量
struct UpdateSqlNode
{
std::string relation_name; ///< Relation to update
std::string attribute_name; ///< 更新的字段,仅支持一个字段
Value value; ///< 更新的值,仅支持一个字段
std::vector<ConditionSqlNode> conditions;
};
对于 update t1 set c1 = 1 这条 sql:
- relation_name 表名
t1 - attribute_name 中存储了列
c1 - value ?
- 而 conditions 中存储的是 where 后的过滤条件,本 sql 中没有 where 子句,所以 conditions 中内容为空。
到此,词法语法解析的过程就结束了
三. resolve 语义解析阶段
函数:resolve_stage_.handle_request()
RC ResolveStage::handle_request(SQLStageEvent *sql_event)
{
...
ParsedSqlNode *sql_node = sql_event->sql_node().get();
Stmt *stmt = nullptr;
rc = Stmt::create_stmt(db, *sql_node, stmt);
...
sql_event->set_stmt(stmt);
return rc;
}
该函数中,最重要的是 Stmt::create_stmt(db, *sql_node, stmt) 该函数根据词法语法解析生成的 SqlNode,生成对应的 Stmt
RC Stmt::create_stmt(Db *db, ParsedSqlNode &sql_node, Stmt *&stmt)
{
stmt = nullptr;
switch (sql_node.flag) {
case SCF_INSERT: {
return InsertStmt::create(db, sql_node.insertion, stmt);
}
case SCF_DELETE: {
return DeleteStmt::create(db, sql_node.deletion, stmt);
}
case SCF_SELECT: {
return SelectStmt::create(db, sql_node.selection, stmt);
}
....
default: {
LOG_INFO("Command::type %d doesn't need to create statement.", sql_node.flag);
} break;
}
return RC::UNIMPLENMENT;
}
sql_node.flag 表示本语句的类型,针对 Update 语句,会调用 UpdateStmt::create(db, sql_node.selection, stmt),根据 SqlNode ,生成 Stmt
在词法语法解析阶段,我们只能检查 sql 语句是否有语法错误,而在语义解析阶段,我们要检测 update 语句中出现的列名,表名等是否存在,以及新的值是否合法。
对于 UpdateStmt::create 函数:
- 要检查语句中出现的表名和列名是否存在
- 新的值的类型是否正确
- 如果语句包含
where子句,还应该生成FilterStmt
RC UpdateStmt::create(Db *db, const UpdateSqlNode &update, Stmt *&stmt)
{
const char *table_name = update.relation_name.c_str();
// check whether the table exists
Table *table = db->find_table(table_name);
...
// check fields type
// update t1 set c1 = 1;
const TableMeta &table_meta = table->table_meta();
const int sys_field_num = table_meta.sys_field_num();
//1.检查 表t1 有没有c1 列
//2.检查 c1 列的类型 与 1 是否匹配
const std::vector<FieldMeta>* fieldMeta = table_meta.field_metas();
bool valid = false;
FieldMeta update_field;
for ( FieldMeta field :*fieldMeta) {
if( 0 == strcmp(field.name(),update.attribute_name.c_str()))
{
if(field.type() == update.value.attr_type())
{
valid = true;
update_field = field;
break;
}
}
}
...
std::unordered_map<std::string, Table *> table_map;
table_map.insert(std::pair<std::string, Table *>(std::string(table_name), table));
UpdateSqlNode U = const_cast<UpdateSqlNode&>(update);
// everything alright
stmt = new UpdateStmt(table,&(U.value), 1,update_field,filter_stmt);
return RC::SUCCESS;
}
到目前为止,我们已经将词法语法解析生成的 sql_node ,转换为了 UpdateStmt。
四. optimize 优化阶段
函数:optimize_stage_.handle_request()
RC OptimizeStage::handle_request(SQLStageEvent *sql_event)
{
RC rc = create_logical_plan(sql_event, logical_operator);//生成逻辑算子
... // rewrite optimize
rc = generate_physical_plan(logical_operator, physical_operator);//生成物理算子
return rc;
}
该函数中,最重要的就是以上两行代码。在SELECT 语句执行流程解析中我们已经介绍了算子相关的知识,下面给出的是 Update 语句的算子树
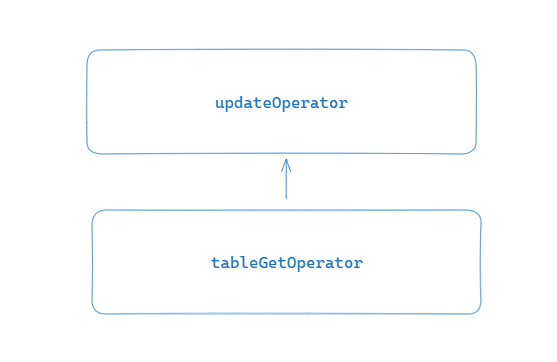
简单 Update 语句的语法树如上图所示:
- tableGet 算子负责将数据从磁盘中读出来
- update 算子负责修改数据并写回磁盘
对于 LogicalPlanGenerator::create_plan 函数:
- 要生成一个
LogicalOperator算子 - 要生成一个
UpdateLogicalOperator算子,并设置其子算子为LogicalOperator - 需要注意
add_child,函数,算子之间正是通过该函数构建成算子树
RC LogicalPlanGenerator::create_plan(
UpdateStmt *update_stmt, unique_ptr<LogicalOperator> &logical_operator)
{
Table *table = update_stmt->table();
FilterStmt *filter_stmt = update_stmt->filter_stmt();
std::vector<Field> fields;//当前表中有哪些列
for (int i = table->table_meta().sys_field_num(); i < table->table_meta().field_num(); i++) {
const FieldMeta *field_meta = table->table_meta().field(i);
fields.push_back(Field(table, field_meta));
}
unique_ptr<LogicalOperator> table_get_oper(new TableGetLogicalOperator(table, fields, false/*readonly*/));//该算子用于从磁盘读写表中数据
std::vector<Value>values;
values.push_back(*(update_stmt->values()));
unique_ptr<LogicalOperator> update_oper(new UpdateLogicalOperator(table,values,*(update_stmt->update_fields())));//该算子用来更新数据
update_oper->add_child(std::move(table_get_oper));//设置子节点
logical_operator = std::move(update_oper);//返回当前算子树的顶层算子
return rc;
}
而 generate_physical_plan 函数,就是将逻辑算子转换为物理算子。

五. execute 执行阶段
函数:execute_stage_.handle_request(sql_event)
经过以上的阶段,我们已经生成了 sql 语句相应的算子树,接下来就是对算子进行 open(),next(),close() 等操作。
首先调用顶层算子的 open 函数,而在算子的 open 函数中,还会递归的调用子算子的 open 函数。同理,在算子的 next 函数中,也会递归的调用子算子的 next 函数。
RC SqlResult::open()
{
if (nullptr == operator_) {
return RC::INVALID_ARGUMENT;
}
Trx *trx = session_->current_trx();
trx->start_if_need();
return operator_->open(trx);//调用子算子的open函数
}
让我们回到最开始的时候:
void SessionStage::handle_request(StageEvent *event)
{
....
(void)handle_sql(&sql_event);
...
RC rc = communicator->write_result(sev, need_disconnect);
...
}
(void)handle_sql(&sql_event) 负责生成相应的算子树,communicator->write_result 负责打开算子树,执行相应流程,获取查询结果并返回给客户端。
RC PlainCommunicator::write_result(SessionEvent *event, bool &need_disconnect)
{
RC rc = write_result_internal(event, need_disconnect);
....
return rc;
}
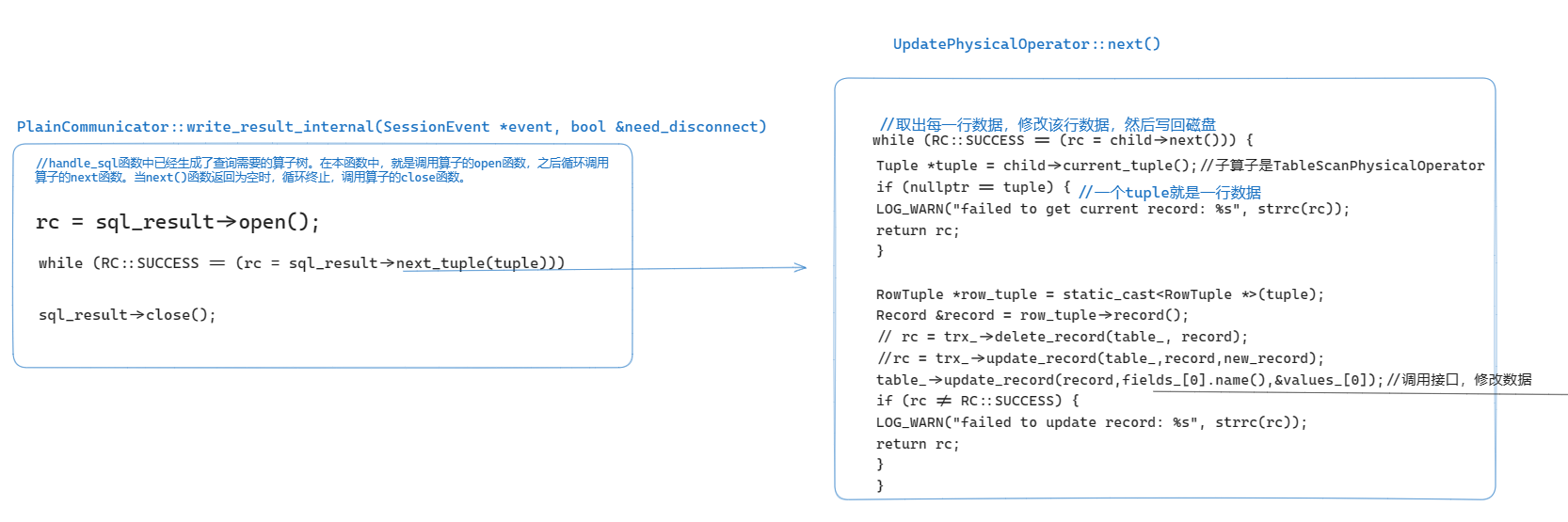
write_result_internal 就会循环调用顶层算子的 open 函数一行一行的处理数据。
RC PlainCommunicator::write_result_internal(SessionEvent *event, bool &need_disconnect)
{
SqlResult *sql_result = event->sql_result();
rc = sql_result->open();//打开顶层算子
Tuple *tuple = nullptr;
while (RC::SUCCESS == (rc = sql_result->next_tuple(tuple))) {//调用顶层算子的next()函数
...
Value value;
rc = tuple->cell_at(i, value);//tuple就是一行数据
....
if (rc == RC::RECORD_EOF) {//数据读取完毕
rc = RC::SUCCESS;
}
RC rc_close = sql_result->close();//递归关闭算子
if (OB_SUCC(rc)) {
rc = rc_close;
}
return rc;
}
}
下面的流程图中介绍了 Update 语句对应的算子操作。